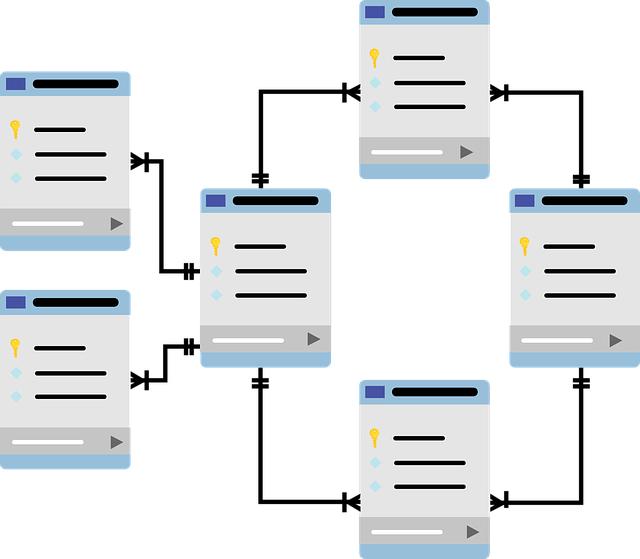
Databáze představují základní stavební kámen většiny moderních aplikací a efektivní práce s nimi je klíčová pro úspěšný vývoj softwaru. Jedním z nejpoužívanějších nástrojů pro manipulaci s daty v databázích je jazyk SQL (Structured Query Language), který nabízí širokou škálu funkcionalit pro efektivní práci s daty. V tomto článku se podíváme na některé z nejvýznamnějších funkcionalit SQL, které vám mohou usnadnit práci s databázemi a zlepšit výkon vašich aplikací.
Přehled SQL klauzulí
V jazyce SQL existuje mnoho klauzulí, které umožňují provádět různé operace nad databází. Mezi nejpoužívanější klauzule patří:
- SELECT: Klauzule SELECT se používá k výběru dat z databáze. Pomocí ní můžeme specifikovat sloupce, které chceme zobrazit, a podmínky, podle kterých chceme data filtrovat.
- FROM: Klauzule FROM určuje, z které tabulky chceme data vybrat. Je důležitá při spojování tabulek a při výběru dat z více tabulek.
- WHERE: Klauzule WHERE slouží k filtrování dat na základě zadaných podmínek. Pomocí ní můžeme specifikovat, jaká data chceme zobrazit.
- ORDER BY: Klauzule ORDER BY se používá k řazení výsledků podle zadaného sloupce. Můžeme určit, zda chceme řadit vzestupně nebo sestupně.
- GROUP BY: Klauzule GROUP BY se používá k seskupení dat podle zadaného sloupce. Často se používá ve spojení s agregačními funkcemi.
Optimalizace dotazů v SQL

V SQL je důležité optimalizovat dotazy, abychom dosáhli co nejefektivnějšího výkonu databáze. Existuje několik základních principů, které můžeme dodržovat při psaní dotazů.
- Indexy: Indexování sloupců v databázi může výrazně zrychlit vyhledávání a filtrování dat. Je důležité správně vybrat sloupce pro indexování a pravidelně provádět údržbu indexů.
- Normalizace: Normalizace tabulek nám pomáhá snížit redundantní data a zajistit konzistenci dat. Díky tomu mohou být naše dotazy jednodušší a efektivnější.
Dalším důležitým faktorem pro optimalizaci dotazů je správné využití klauzulí WHERE, GROUP BY a JOIN. Klauzule WHERE nám pomáhají filtrovat data a omezovat počet řádků vrácených dotazem.
Při psaní dotazů je také dobré minimalizovat použití funkcí a operací nad sloupci, které mohou snížit výkon dotazu. Je lepší provést výpočty a transformace mimo dotaz a pracovat s již připravenými daty.
Pokročilé agregační funkce SQL
V SQL lze využívat nejen základní agregační funkce jako jsou SUM, AVG, MIN a MAX, ale existují také pokročilé agregační funkce, které umožňují provádět složitější výpočty nad daty v databázi. Tyto funkce poskytují ještě větší flexibilitu a možnost tvorby komplexních dotazů.
Mezi patří například:
- COUNT(DISTINCT column_name): Tato funkce spočítá počet unikátních hodnot v daném sloupci tabulky. Je užitečná například pro zjištění počtu různých kategorií v daném sloupci.
- GROUP_CONCAT(column_name): Tato funkce slouží k spojení hodnot v daném sloupci do jednoho řetězce. Může být využita například pro zobrazení všech hodnot v daném sloupci jako jednoho textového řetězce.
Díky pokročilým agregačním funkcím můžete efektivněji pracovat s daty v databázi a generovat výstupy přesně podle svých potřeb. Jejich správné využití může signifikantně zjednodušit a zrychlit Vaše SQL dotazy.
Využití subdotazů v SQL
je velmi užitečným nástrojem pro získávání specifických dat z databáze. Subdotazy jsou dotazy vložené do hlavního dotazu, které slouží k filtrování a získávání dat podle konkrétních podmínek.
Jedním z hlavních je filtrování dat na základě výsledků jiného dotazu. Například můžeme použít subdotaz k získání seznamu produktů, které mají vyšší cenu než průměrná cena v tabulce.
Dalším častým využitím subdotazů je porovnání hodnot s jinými daty v databázi. To může být užitečné například při hledání záznamů, které mají podobné vlastnosti jako konkrétní záznam, který nás zajímá.
Subdotazy mohou být také využity k vytvoření komplexních filtrů a podmínek. Pomocí kombinace logických operátorů a podmínek v subdotazech můžeme získat přesně taková data, jaká potřebujeme.
Je důležité mít na paměti, že použití subdotazů může mít vliv na výkon databáze, zejména u složitých dotazů. Je proto důležité optimalizovat dotazy a zvolit efektivní způsob využití subdotazů, aby nedošlo k zbytečné zátěži serveru.
Efektivní práce s indexy
Při práci s databázemi či tabulkami je klíčové efektivně využívat indexy k vyhledávání a filtrování dat. Indexy umožňují databázi rychleji nalézt požadované informace a výrazně zrychlují provádění dotazů. Správné vytvoření a správa indexů může zásadním způsobem ovlivnit výkon celé aplikace.
Vytváření indexů by mělo být provedeno na sloupcích, které se často používají pro filtrování nebo řazení dat. Primární klíče jsou automaticky indexovány, ale v některých případech může být výhodné vytvořit index i na jiných sloupcích. Je důležité zohlednit potřeby konkrétní aplikace a provést analýzu dotazů, aby bylo možné určit, kde je nejvíce vhodné vytvořit indexy pro maximalizaci výkonu.
Indexy mohou být vytvářeny i na kombinaci více sloupců, což se hodí pro složitější dotazy, které vyžadují filtrování podle různých kritérií. Při vytváření indexu na kombinaci sloupců je důležité zvážit pořadí sloupců v indexu, aby bylo dosaženo optimálního výkonu dotazů.
Při úpravě dat v tabulce je důležité dbát na to, aby indexy byly správně udržovány a aktualizovány. Při vkládání, mazání nebo aktualizaci dat je třeba zajistit, aby indexy zůstaly konzistentní a efektivní. Nesprávné udržování indexů může vést k degradaci výkonu aplikace a zpomalování provádění dotazů.
Transakční zpracování v SQL
V databázových systémech je transakce soubor operací, které musí být provedeny všechny nebo žádná. je důležitý koncept pro zajištění konzistence a integrity dat v databázi. Transakce mohou obsahovat různé operace, jako jsou vkládání, aktualizace nebo mazání záznamů v databázi.
Transakce v SQL jsou obvykle zahájeny klíčovým slovem „BEGIN TRANSACTION“ a ukončeny klíčovým slovem „COMMIT“ nebo „ROLLBACK“. Klíčové slovo „COMMIT“ potvrzuje provedení operací v transakci, zatímco klíčové slovo „ROLLBACK“ vrací databázi do stavu před zahájením transakce, tímto se zruší provedené operace.
Při transakčním zpracování v SQL je důležité dbát na to, aby byla splněna ACID vlastnosti transakcí. Toto zajišťuje, že transakce jsou atomické (provedou se všechny operace nebo žádná), konzistentní (zachovávají integritu dat), izolované (neovlivňují se navzájem) a trvalé (změny jsou trvale uloženy v databázi).
Při navrhování databázové architektury je třeba pečlivě zvážit transakční zpracování, aby byla zajištěna správná manipulace s daty a minimalizováno riziko chyb. Správné využití transakcí v SQL může být klíčové pro dosažení úspěchu aplikace, která využívá relační databázi.
Využití pokročilých funkcionalit SQL může výrazně zvýšit efektivitu práce s databázemi. Díky možnosti vytvářet složité dotazy, kombinovat data z různých tabulek nebo provádět agregační operace lze získat užitečné informace a analýzy pro podnikové rozhodování. Tímto způsobem mohou firmy zlepšit své výsledky, optimalizovat procesy a zvýšit konkurenceschopnost na trhu. Je tedy vhodné se seznámit s možnostmi, které SQL nabízí, a využívat je na maximum pro úspěšné řízení a analýzu dat v rámci firemních databází.



